
Si vous vous intéressez au référencement naturel de votre boutique en ligne, vous avez sûrement déjà entendu parler d’un fichier important qui se situe à la racine de votre site : le robots.txt.
Indispensable pour optimiser le parcours des robots des moteurs de recherche, il permet de leur indiquer les pages qu’ils peuvent explorer et celles qu’ils ne peuvent pas.
Particulièrement utile sur les sites e-commerce qui contiennent de nombreuses URLs dynamiques liées aux filtres de tris, aux facettes ou encore aux pages de commandes, sa configuration doit être méticuleuse.
Qu’est-ce que le fichier robots.txt ?
Comme son nom l'indique, le fichier robots.txt est un fichier au format texte situé à la racine de votre site. Il est uniquement destiné aux robots des moteurs de recherche.
Il est principalement utilisé pour indiquer les différentes URLs d’un site qui ne sont pas autorisées à l’exploration.
Découvrez notre article complet sur le SEO et les URLs.
N’étant pas destiné aux internautes, il peut parfaitement interdire l'accès à une partie du site aux robots des moteurs de recherche, tout en laissant cette dernière accessible aux visiteurs.
Pour savoir si vous avez un fichier robots.txt sur votre site, il vous suffit de taper votre domaine racine et d'ajouter “/robots.txt” à la fin de l'URL. Si aucune page n'apparaît, c'est que vous n'en avez pas.
La plupart du temps, il est créé par le webmaster ou l'administrateur du site, qui va le glisser dans le répertoire prévu sur son serveur FTP. Il peut ensuite être mis à jour autant de fois que nécessaire.
Si vous utilisez la solution e-commerce WiziShop, celui-ci est automatiquement généré et configuré. Vous trouverez en fin d’article une explication des différentes configurations présentes par défaut.
Comment fonctionne le fichier robots.txt ?
Les deux missions principales des moteurs de recherche sont les suivantes :
- Parcourir l'ensemble du Web pour découvrir le contenu qui est créé en permanence ;
- Indexer correctement ce contenu pour qu'il soit diffusé de façon pertinente aux internautes en recherche d'informations.
Pour mener à bien ces missions, les robots des moteurs de recherche explorent des milliards d’URLs sur de nombreux sites Web.
Les robots analysent donc le fichier robots.txt afin d’identifier des consignes d’exploration. Par conséquent, il s'agit d’un contenu que les robots consultent fréquemment.
Ils s'assurent des directives particulières qui peuvent leur interdire, par exemple, d'explorer certaines pages ou parties du site.
Attention, le fichier robots.txt ne sert pas à gérer l’indexation de vos pages. Il n’est pas destiné à cette utilisation. Si vous possédez des pages dans votre site que vous souhaitez ne pas indexer, la balise noindex est plus adaptée.
Concernant les URLs dynamiques, propres au e-commerce, qui ne sont pas présentes dans la structure basique de votre site (navigation à facettes, filtres de tris, moteur de recherche interne, etc), c’est une bonne pratique d'empêcher les différents robots de visiter ces pages.
Quels sont les intérêts du fichier robots.txt ?
Vous l'aurez compris, l'intégration d'un fichier robots.txt sur votre site Web est souvent bénéfique pour faciliter l’exploration vis-à-vis des robots des moteurs de recherche.
Ce fichier présente de nombreux avantages et peut devenir bénéfique à votre référencement naturel.
Manager le crawl des robots des moteurs de recherche
Le crawl est une étape clé en SEO. Pour un moteur de recherche, cette notion représente le parcours des robots sur les différentes URLs présentes sur Internet.
Ces URLs explorées peuvent être des contenus HTML, des images, des PDF, des fichiers JS et CSS, et bien d’autres.
Seulement, les ressources des moteurs de recherche ne sont pas illimitées. La popularité, l'ancienneté ou encore le rythme de publication du site vont déterminer le temps d’exploration alloué pour chaque site. Ce temps d’exploration s'appelle le budget crawl.
La notion de budget crawl concerne principalement les gros sites avec des milliers de pages. Si votre site est plus petit, les problématiques SEO liées à ce budget ne vous concernent pas.
En revanche, pour reprendre l’exemple du e-commerce, il est possible que le site que vous avez construit et que vous voyez en tant qu'utilisateur ne soit pas le même pour les robots. Si vos différentes pages de filtres à facettes ou de tris vous permettent de fluidifier la navigation des visiteurs, il est fort probable que les robots, eux, voient plusieurs milliers de pages différentes.
Dans ce cas là, le budget crawl peut donc entrer en compte et avoir des répercussions sur votre SEO car les robots penseront, à tort, que votre site est trop chargé de pages inutiles.
Il est donc important de faire crawler uniquement des URLs pertinentes pour optimiser le passage des robots.
Si vous recherchez une solution pour analyser le parcours des robots des moteurs de recherche sur votre site, découvrez notre article sur l’analyse de logs ainsi que l’outil Seolyzer.
Le fichier robots.txt est particulièrement utile pour éviter que les robots des moteurs de recherche ne visitent des pages sans le moindre intérêt. Il va vous permettre de prévoir à l’avance ces éventuelles problématiques en le configurant efficacement.
Éviter de se perdre dans le moteur de recherche interne
Lorsque vous faites des recherches internes sur votre site, cela génère automatiquement des URLs.
Les pages de ces résultats de recherches internes n'ont souvent aucun intérêt en matière de référencement et sont infinies. Il peut donc être pertinent de les bloquer, par l'intermédiaire de votre fichier robots.txt.
De la sorte, vous empêchez l’exploration par les robots des moteurs de recherche.
Indiquer l’URL du sitemap
Le sitemap est un fichier qui liste toutes les URLs pertinentes d'un site Internet.
Le but principal du sitemap est de faciliter le parcours du site par les robots des moteurs de recherche. Grâce à lui, ils visitent plus facilement les pages d'un site.
Pour permettre aux robots des moteurs de recherche de trouver votre sitemap, il vous est possible d'ajouter un lien vers ce dernier, directement dans votre fichier robots.txt sous cette forme :
Sitemap: https://www.exemple.fr/sitemap.xml
Cela peut-être intéressant pour indiquer l’emplacement de votre sitemap aux différents moteurs de recherche, mais je vous conseille surtout de l’ajouter directement dans votre outil Search Console de Google ainsi que dans Bing Webmaster Tools.
Les autres utilisations du fichier robots.txt
Certains usages du robots.txt sont assez courants même si la fonction principale de celui-ci n’est pas dédiée à ces utilisations.
- Éviter de visiter l’espace d’administration
Le front office d'un site Internet désigne toute la partie qui est vue par les internautes. A contrario, les sites web possèdent souvent un back-office. Il s'agit, en quelque sorte, des coulisses des CMS, c'est-à-dire l'interface qui permet à l'administrateur de gérer le site Web.
Bien évidemment, ces pages n'ont aucun intérêt pour les internautes. La plupart des CMS vont bloquer également leur exploration via le fichier robots.txt.
La bonne pratique est d’utiliser une protection par mot de passe. Cette authentification empêche les robots d’accéder à la partie du site. Cela évitera également de divulguer votre URL de connexion à votre espace d’administration.
- Les landing pages
Si vous envoyez fréquemment des newsletters à vos clients et prospects, vous êtes certainement amenés à créer toutes sortes de landing page. Ces dernières ont essentiellement un objectif publicitaire.
Elles visent, par exemple, à présenter un événement particulier ou une offre spéciale. Elles n'ont donc pas de réel intérêt en matière de référencement. Une fois l'événement passé, ces landing pages sont souvent supprimées.
Là encore, il peut être tentant de les ajouter dans le robots.txt. Mais la bonne pratique est de gérer ces pages via des balises noindex. D’autant plus qu’en visitant votre fichier robots.txt, vos concurrents pourront facilement tomber sur vos pages publicitaires.
- Les pages dupliquées
De manière générale, le contenu dupliqué nuit au référencement d'un site Internet. Si les robots d’exploration constatent que vos pages contiennent du duplicate content, votre positionnement risque de chuter.
La pratique courante va être de gérer les pages dupliquées via le fichier robots.txt pour éviter que les moteurs de recherche ne parcourent ces URLs mais la balise noindex ou encore la balise canonical peuvent être plus adaptées.
Comment tester le fichier robots.txt ?
Comme toute autre partie d'un site Internet, votre fichier robots.txt doit être testé pour vérifier son efficacité. Cela permet de détecter les éventuelles erreurs de configurations et d'y apporter, si nécessaire, quelques corrections.
Pour tester l'efficacité de votre fichier robots.txt, il vous suffit d'utiliser l'outil Google Search Console, accessible dans l’ancienne version :
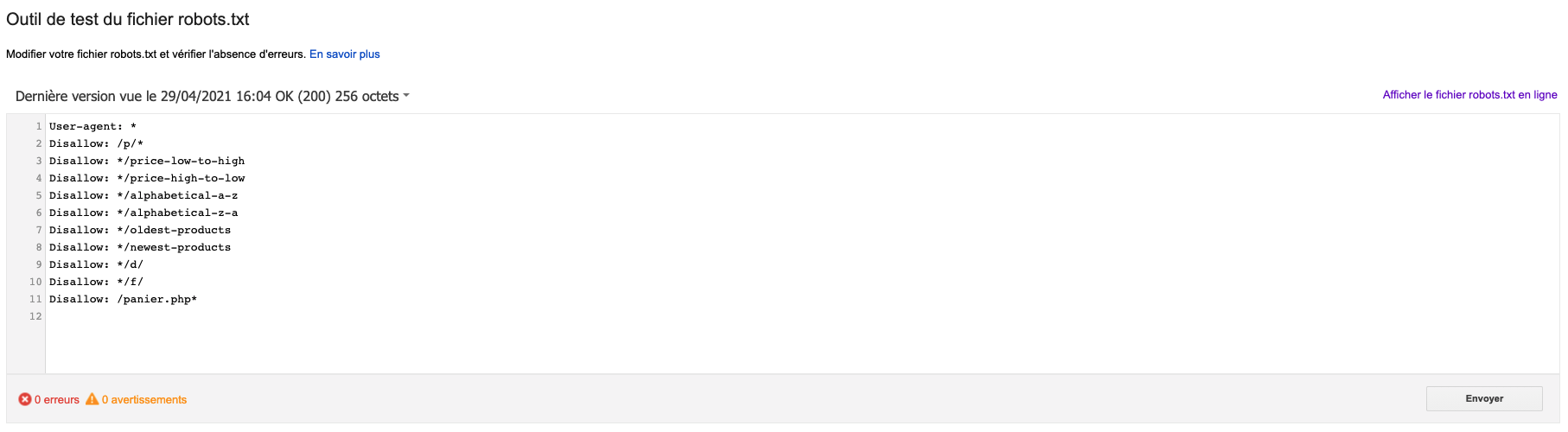
Celui-ci permet de tester des URLs, pour savoir si ces dernières sont accessibles ou non. Il vous suffit de l’indiquer dans le champ adapté pour vérifier si elle est bloquée ou non pour Google.
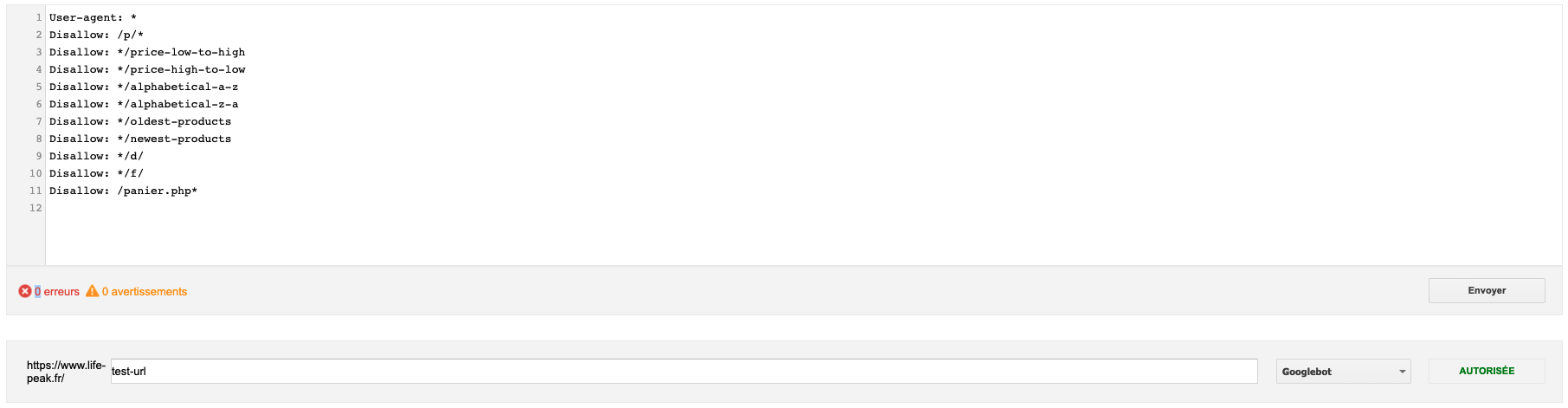
Exemple avec une URL autorisée :
Exemple avec une URL bloquée :
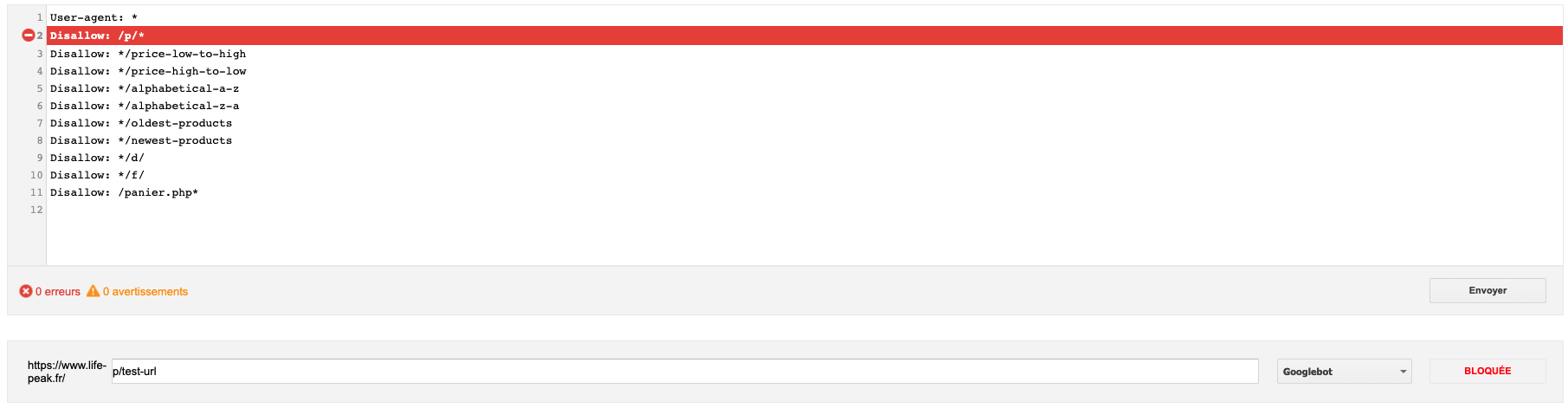
Ce type de test est particulièrement utile pour être certain que vous ne bloquez pas une partie de votre contenu pertinent ou certaines sections de votre site Web de manière involontaire.
Si vous le souhaitez, vous pouvez également utiliser des outils en ligne comme https://technicalseo.com/tools/robots-txt/.
Les syntaxes du fichier robots.txt
Au sein du fichier robots.txt plusieurs syntaxes sont possibles. Voici celles qui sont le plus couramment utilisées :
- User-agent : Permet de spécifier à quel robot d’exploration les instructions s’adressent (exemple : Googlebot ou Bingbot). Au sein du même fichier, vous pouvez donc spécifier des consignes différentes selon les user-agents.
- Disallow : Cette instruction indique que les robots d’exploration ne peuvent pas explorer une URL ou un dossier.
- Allow : Cette instruction indique que les robots d’exploration peuvent explorer une URL même si celle-ci est dans un dossier interdit avec un “Disallow”.
- Crawl-delay : Le crawl-delay permet d’indiquer le délai à respecter entre l’exploration des différentes URLs. Cette consigne n’est pas prise en compte par Google.
- Sitemap : Permet de spécifier l’emplacement du sitemap. Elle est surtout utilisée pour les autres moteurs de recherche étant donné que Google et Bing vous proposent de l’ajouter directement dans leurs outils pour webmaster.
Le robots.txt sur les boutiques WiziShop
Comme je l’ai mentionné en début d’article, le fichier robots.txt des boutiques WiziShop se génère automatiquement.
Si vous vous demandez ce que représente les différentes instructions qui sont présentes à l’intérieur, voici les explications :

Pour résumer, la configuration par défaut du robots.txt des boutiques WiziShop permet de bloquer l’exploration des URLs liées aux comptes clients et aux pages paniers. Cette instruction est valable pour l’ensemble des user-agents.
Ce fichier est accessible dans votre back office. Vous pouvez donc ajouter diverses configurations pour bloquer l’exploration des URLs de votre choix.
Le fichier robots.txt est efficace mais occasionne des pertes de PageRank. C’est pour cette raison que nous travaillons actuellement sur une méthode alternative afin de réduire et masquer au maximum les liens présents vers ces pages.
WiziShop vous donne également la possibilité d'éditer ce fichier en ajoutant des instructions spécifiques. En revanche, ce fichier est très sensible, donc utilisez-le uniquement si vous savez ce que vous faites !
Une mauvaise configuration peut entraîner le blocage d’exploration sur des URLs importantes de votre boutique et occasionner des problématiques SEO.
Le fichier robots.txt est un outil indispensable si vous souhaitez garder la maîtrise de l'exploration des pages de votre site e-commerce. Si aucun fichier robots.txt n'est créé, toutes les URLs découvertes par les robots seront susceptibles d'être explorées et de se retrouver dans les résultats des moteurs de recherche.






